搜索引擎的工作原理是什么及发展历史?
搜索引擎是应用在网络上方便的检索信息而产生的。所有搜索引擎的祖先是1990年由加拿大蒙特利尔大学的学生Alan发明的,虽然当时万维网还没出现,但是在网络中传输文件已经相当频繁了,由于大量的文件散步在各个分散的FTP主机中,查询起来非常不便于是Alan等想到了开发一个可以用文件名查找文件的系统,于是便有了ARCHIE,这就是最早的搜索引擎雏形。搜索引擎的工作原理主要就是四个步骤:爬行,抓取,检索,显示。搜索引擎放出蜘蛛在互联网上爬行,目的是为了发现新的网站和最新的网页内容,从而经过搜索引擎特定程序分析后决定是否抓取这些信息,抓取后然后将其放到索引数据库中,顾客在搜索引擎网站上检索信息时,就会在结果页上出现与检索词相关的信息,并根据与检索词的相关度进行拍序,这就是搜索引擎的工作原理和步骤。了解搜索引擎工作原理是从事SEO人员需具备的基本知识。搜索引擎工作原理是什么?SEO优化背后的原理?
搜索引擎的工作原理总共有四步: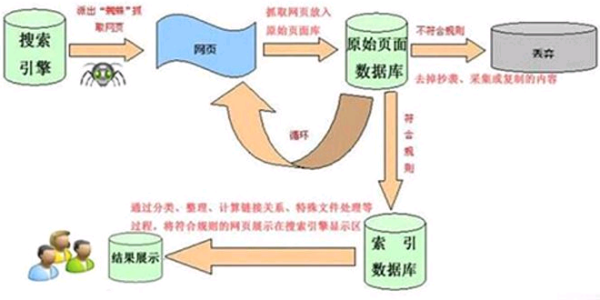
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎内部资料所决定的。比如:某一种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
定义
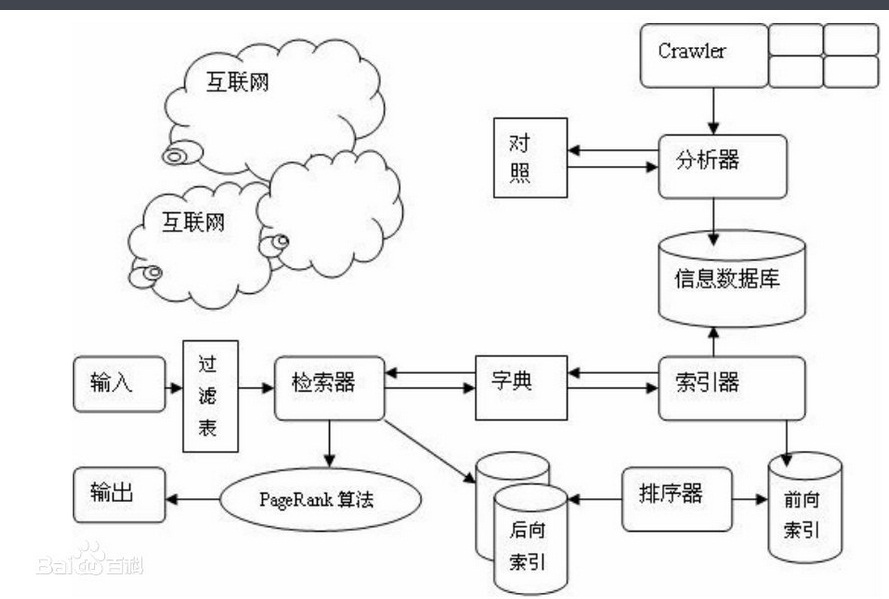
一个搜索引擎由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter
Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。Alan Emtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件 。
由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。Jughead是后来另一个Gopher搜索工具。
什么是搜索引擎,其工作原理是什么
一、什么叫搜索引擎?在Internet上有上百亿可用的公共Web页面,即使是最狂热的冲浪者也不会访问到所有的页面,而只能看到其中的一小部分,更不会在这浩瀚的Web海洋中发现你那即使精彩却渺小的一隅。当然你可以为你的存在做广告,可以用大大的字把你的URL刻在你的身体上,然后裸体穿过白宫草坪,但你得保证媒体正好在那里,并注视到了这一切。与其这样做,不如好好去理解搜索引擎是如何工作的?又怎样选择和使用"keywords"(关键词)等等。
本文的目的就是让众多的页面设计者在了解搜索引擎的基础上,寻求如何使自己的页面在搜索引擎索返回的列表中获得好的排列层次的方法。
"搜索引擎"这个术语一般统指真正意义上的搜索引擎(也就是全文检索搜索引擎)和目录(即目录式分类搜索引擎),其实他们是不一样的,其区别主要在于返回的搜索结果列表是如何编排的。
1、目录
目录(比如Yahoo!)返回的列表是由人工来编排的。
这类引擎提供了一份人工按类别编排的网站目录,各类下边排列着属于这一类别的网站的站名和网址链接,再记录一些摘要信息,对该网站进行概述性介绍(摘要可能是你提交过去的,也可以是引擎站点的编辑为你的站点所做的评价)。人们搜索时就按相应类别的目录查询下去。
这类引擎往往还伴有网站查询功能,也称之为网站检索,即提供一个文字输入框和一个按钮。我们可以在文字框中输入要查找的字、词或短语,再点击按钮,便会在目录中查找相关的站名、网址和内容提要,将查到的内容列表送过来。目前国内Sohoo、常青藤等都是这种搜索方式。
2、搜索引擎
搜索引擎(如HotBot)是自动创建列表的。
搜索引擎看起来与目录的网站查询非常相似,也提供一个文字输入框和按钮,使用方法也相同,而且有些也提供分类目录,但两者却有本质上的区别。
目录的资料库中,搜集保存的是各网站的站名、网址和内容提要;搜索引擎的资料库中,搜集保存的则是各网站的每一个网页的全部内容,范围要大得多。
搜索引擎是以全文检索的方式工作的。全文检索查到的结果不是站名、网址和内容提要,而是与你输入的关键词相关的一个个网页的地址和一小段文字。在这段文字中,可能没有你输入的那个关键词,它只是某一网页的第一段话,甚至是一段无法看懂的标记,但在这个网页中,一定有你所输入的那个关键词,或者相关的词汇。打个比方说,网站查询可以查到网上有哪些报纸,如《文汇报》、《大公报》,而全文检索则可以查到网上这些报纸的每一篇文章中的词汇。
3、两者相结合的搜索引擎
某些搜索引擎同时也提供目录。包含在搜索引擎中的目录通常质量比较高,也能从那里找到许多好站点。因为即使你把你的站点提交过去,也并不能保证一定被加到目录中去,他们把注意力放在那些已经在别的目录中存在的站点上,并有选择地寻找有吸引力的加到自己的目录中。
搜索引擎和目录各有各自不可替代的功用。目录比较简单,要想获得一个好的排列层次,除了你努力创建一个好内容的高品质站点外别无他法。搜索引擎复杂得多,它们随时都在自动地索引众多WEB站点的最新网页,所以常常会发现目录所不能得到的信息。如果你改动了你的页面,搜索引擎还随时会发现这个变化,并重新排列你在列表中的位置。而目录就做不到。下面专门讨论搜索引擎的工作原理以及如何提高在搜索引擎列表中的排列位置。
参考资料:
http://www.yuan.sc.cn/cpc/buildweb/search101.htm
按照信息搜集方法和服务提供方式的不同,搜索引擎系统可以分为三大类:
1.目录式搜索引擎:以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中。信息大多面向网站,提供目录浏览服务和直接检索服务。该类搜索引擎因为加入了人的智能,所以信息准确、导航质量高,缺点是需要人工介入、维护量大、信息量少、信息更新不及时。这类搜索引擎的代表是:Yahoo、LookSmart、Open Directory、Go Guide等。
2.机器人搜索引擎:由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户。服务方式是面向网页的全文检索服务。该类搜索引擎的优点是信息量大、更新及时、毋需人工干预,缺点是返回信息过多,有很多无关信息,用户必须从结果中进行筛选。这类搜索引擎的代表是:AltaVista、Northern Light、Excite、Infoseek、Inktomi、FAST、Lycos、Google;国内代表为:"天网"、悠游、OpenFind等。
3.元搜索引擎:这类搜索引擎没有自己的数据,而是将用户的查询请求同时向多个搜索引擎递交,将返回的结果进行重复排除、重新排序等处理后,作为自己的结果返回给用户。服务方式为面向网页的全文检索。这类搜索引擎的优点是返回结果的信息量更大、更全,缺点是不能够充分使用所使用搜索引擎的功能,用户需要做更多的筛选。这类搜索引擎的代表是WebCrawler、InfoMarket等。
……
主 要 技 术
一个搜索引擎由搜索器、索引器、检索器和用户接口等四个部分组成。
1.搜索器
搜索器的功能是在互联网中漫游,发现和搜集信息。它常常是一个计算机程序,日夜不停地运行。它要尽可能多、尽可能快地搜集各种类型的新信息,同时因为互联网上的信息更新很快,所以还要定期更新已经搜集过的旧信息,以避免死连接和无效连接。目前有两种搜集信息的策略:
● 从一个起始URL集合开始,顺着这些URL中的超链(Hyperlink),以宽度优先、深度优先或启发式方式循环地在互联网中发现信息。这些起始URL可以是任意的URL,但常常是一些非常流行、包含很多链接的站点(如Yahoo!)。
● 将Web空间按照域名、IP地址或国家域名划分,每个搜索器负责一个子空间的穷尽搜索。
搜索器搜集的信息类型多种多样,包括HTML、XML、Newsgroup文章、FTP文件、字处理文档、多媒体信息。
搜索器的实现常常用分布式、并行计算技术,以提高信息发现和更新的速度。商业搜索引擎的信息发现可以达到每天几百万网页。
2.索引器
索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
索引项有客观索引项和内容索引项两种:客观项与文档的语意内容无关,如作者名、URL、更新时间、编码、长度、链接流行度(Link Popularity)等等;内容索引项是用来反映文档内容的,如关键词及其权重、短语、单字等等。内容索引项可以分为单索引项和多索引项(或称短语索引项)两种。单索引项对于英文来讲是英语单词,比较容易提取,因为单词之间有天然的分隔符(空格);对于中文等连续书写的语言,必须进行词语的切分。
在搜索引擎中,一般要给单索引项赋与一个权值,以表示该索引项对文档的区分度,同时用来计算查询结果的相关度。使用的方法一般有统计法、信息论法和概率法。短语索引项的提取方法有统计法、概率法和语言学法。
索引表一般使用某种形式的倒排表(Inversion List),即由索引项查找相应的文档。索引表也可能要记录索引项在文档中出现的位置,以便检索器计算索引项之间的相邻或接近关系(proximity)。
索引器可以使用集中式索引算法或分布式索引算法。当数据量很大时,必须实现即时索引(Instant Indexing),否则不能够跟上信息量急剧增加的速度。索引算法对索引器的性能(如大规模峰值查询时的响应速度)有很大的影响。一个搜索引擎的有效性在很大程度上取决于索引的质量。
3.检索器
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。
检索器常用的信息检索模型有集合理论模型、代数模型、概率模型和混合模型四种。
4.用户接口
用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。主要的目的是方便用户使用搜索引擎,高效率、多方式地从搜索引擎中得到有效、及时的信息。用户接口的设计和实现使用人机交互的理论和方法,以充分适应人类的思维习惯。 用户输入接口可以分为简单接口和复杂接口两种。
简单接口只提供用户输入查询串的文本框;复杂接口可以让用户对查询进行限制,如逻辑运算(与、或、非;+、-)、相近关系(相邻、NEAR)、域名范围(如.edu、.com)、出现位置(如标题、内容)、信息时间、长度等等。目前一些公司和机构正在考虑制定查询选项的标准。
搜索引擎的搜索原理是什么?
搜索引擎的工作原理:1、搜集信息
搜索引擎的信息搜集基本都是自动的。
搜索引擎利用称为网络蜘蛛的自动搜索机器人程序来连上每一个网页上的超链接。
机器人程序根据网页连到其中的超链接,就像日常生活中所说的一传十,十传百,从少数几个网页开始,连到数据库上所有到其他网页的链接。
理论上,若网页上有适当的超链接,机器人便可以遍历绝大部分网页。
2、整理信息
搜索引擎整理信息的过程称为“创建索引”。
搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
3、接受查询
用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。
搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
目前,搜索引擎返回主要是以网页链接的形式提供的,这样通过这些链接,用户便能到达含有自己所需资料的网页。
通常搜索引擎会在这些链接下提供一小段来自这些网页的摘要信息以帮助用户判断此网页是否含有自己需要的内容。
搜索引擎工作原理是什么??
搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。